Reinforce AI konferencia

2019.03.29. • olvasási idő:
Ott voltunk a Reinforce-on, Magyarország első AI konferenciáján.

credit to: JSSC
Ez volt az első nagyobb esemény itthon, ami a mesterséges intelligenciát helyezte középpontba, de szervezésben és előadói felhozatalban is felért az olyan híres magyar konferenciák mellé mint a Craft vagy a Crunch. A konferenciára olyan cégektől érkeztek előadók mint a Google, IBM, OpenAI, Uber, Twitter, RapidMiner…stb. A konferencia két napja alatt a gépi tanulás, illetve azon belül még számos változatos téma technológiai részleteiről halhatott előadást a több, mint 500 résztvevő. Íme az a három, amik a legfontosabbak, ha az aktuális legjobb technológiákhoz kapcsolódó hands-on tudást szeretnél kapni.
Stefan Otte: Practical Pytorch
Az előadáson a népszerű PyTorch került részletes bemutatásra, mely egy gyors és flexibilis deep learning framework. Stefan többször is hivatkozott rá, hogy a PyTorch használata semmivel sem bonyolultabb, mint a Numpy könyvtáré. PyTorch esetén a tensorokra tekinthetünk úgy, mint multidimenzionális tömbökre, melyek könnyedén futtathatók GPU-n is. A PyTorch további előnye hogy dinamikusan on the fly módon készíthetünk számítási gráfot, illetve módosíthatjuk a modellt. Az előadás rendkívül sok kódrészletet tartalmazott, már-már egy notebookhoz hasonlított, ami szerintem sok mérnök tetszését elnyerte. Az előadás legfőbb célja az volt, hogy a végére egy olyan alaptudást adjon, amivel bárki hozzá kezdhet a Pytorch alkalmazásához. Végezetül, összehasonlítva a PyTorch és a TensorFlow közti különbségeket, a dinamizmus mindenképp a PyTorch mellett szól, azonban a modell éles rendszerbe történő átültetése a TensorFlow esetén könnyebb.

Ha kíváncsi vagy Stefan PyTorch tutorial-jára, az alábbi linken megtalálod: https://github.com/sotte/pytorch_tutorial
PARIS BUTTFIELD-ADDISON es MARS GELDARD: On-device Neural Style Transfer
Ezt az prezentációt két előadó tartotta Tazmániából, akik nagyon érdekfeszítő témákról beszéltek. Először a Neural Style Transfer-ről (NST), illetve a személyes adatok biztonságáról majd arról, hogy az On-device megoldások miben tudják ezt támogatni.
Magának az NST-nek az alapgondolata az, hogy miként lehet egy műalkotásnak a stílusjegyeit átültetni egy hasonló alkotásba, például egy selfie-t hogyan lehet úgy átalakítani, hogy úgy tűnjön, mintha kézzel rajzolták volna.

credit to @DmitryUlyanovML
A fenti képen látható, hogy ezt hogyan is kell elképzelni a valóságban. A mély neurális hálók segítségével a gépek képesek meghatározni azt, hogy mit is jelent maga a stílus, illetve a tartalom; a kettőt ötvözve bámulatos eredményeket kaphatunk. Talán fel se tűnik, de a mindennapjainkban is rengetegszer használjuk ezt a technológiát, például amikor egy filter-t használunk fényképezésnél.
Hogyan kapcsolódik mindehhez a személyes adatok védelme? Sok esetben, amikor hasonló szolgáltatásokat szeretnénk igénybe venni, maga a számítás nem a saját eszközünkön történik meg, hanem a telefonunk küldi el az adatokat egy szerverre, ahol megtörténnek a különböző számítások, ezután visszaküldik az eredményt nekünk. Az adat azonban ebben a folyamatban kikerül az eszközünkről, ezzel lehetőséget ad arra, hogy azt mások megszerezzék. Az előadók a prezentáció során azonban nem csak elméletben beszéltek az On-device számítások fontosságáról, hanem csináltak egy demo-t is, ahol mindenki maga láthatta élőben a működő rendszert.
https://github.com/thesecretlab/ReinforceConf2019
Josh Tobin: TROUBLESHOOTING DEEP NEURAL NETWORKS
Josh Tobin előadásával kezdődött a második nap, ahol sokak számára érdekes kérdésre adott választ, a mély neurális hálók debuggolásával kapcsolatosan. Miért is kell ezzel a területtel kiemelten foglalkozni? Egy deep learning technológiára támaszkodó projekt életciklusa során az idő 80-90%-a telik debugolással és optimalizációval, míg 10-20% implementálással. A nehézséget azonban az jelenti, hogy sok esetben nem lehet a komplex rendszer eredményeit reprodukálni, a modell teljesítményvesztésének számos forrása lehet, az eredmény rendkívül érzékeny a hyper-paraméterek és a tanító adathalmaz kisebb változtatásaira is. Ahhoz, hogy hibamentes deep learning modellt tudjunk alkalmazni, a modell építésre iteratív folyamatként kell tekintenünk. Josh legfőbb célja az volt, hogy egy pörgős, dinamikus előadással bemutassa hogyan előzhetjük meg a bugok keletkezését és milyen árulkodó jelek lehetnek a modellünkben azok létezésére.
http://josh-tobin.com/troubleshooting-deep-neural-networks.html
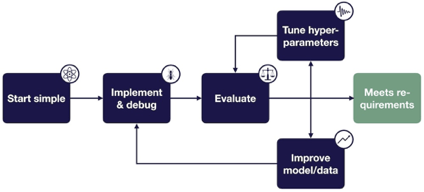
credit to: @josh_tobin_
Összegezve, nekem nagyon tetszett a konferencia, jobbnál jobb előadásokat hallgathattam meg a szívemhez közel álló témákban. Továbbá érdekes volt betekintést nyerni egy ilyen nagyszabású esemény szervezői hátterébe, örülök, hogy segíthettem a rendezvény sikeres lebonyolításában. Alig várom a következőt!
 Vissza a blogbejegyzésekhez
Vissza a blogbejegyzésekhez