Python – Kezdetek
2015.04.15. • olvasási idő:
Egy ideje már gondolkodtam azon, hogy Python-os bejegyzést is írjak, de egyrészt a DMLab-ban nálam jóval tapasztaltabb Python-os kollégák is vannak, másrészt a Python kezdeteihez tele a net ismertetőkkel, leírásokkal és tutorialokkal, ha pedig már a kódolás közben nem tudnánk valamit, elég nagy valószínűséggel korábban már megkérdezte valaki az adott dolgot Stackoverflow-n, vagy ha nem, a mi kérdésünkre is egészen biztosan nagyon hamar érkezik válasz.

Harmadrészt viszont a több mint 54.000 Python modulnak köszönhetően a Python nyelv annyira sokrétű, hogy futószalagon lehetne gyártani a bejegyzéseket (amiket szerencsére bőven van aki olvas, köszönet érte 🙂 ) A fentiek értelmében, és mert persze adatbányászattal foglalkozunk, Python-os témában is csak egy-két érdekességnek illetve hiánypótlónak gondolt írást tervezek, melyek közül az első értelem szerűen ez a kedvcsinálónak szánt bevezető poszt, ami azon adatelemzők számára lehet hasznos, akik még csak tervezgetik a Python-ban való elmélyülést vagy csak nemrég írták meg első szkriptjeiket. De persze azt sem tartom kizártnak, hogy a tapasztaltabbak is találhatnak némi újdonságot a következő sorokat olvasva.
Érdekel az adatelemzés? Elsajátítanád a data science alapjait? Akkor a Dataskool Data science képzésünket neked találtuk ki!
Indulj el a data scientistté válás útján: tanuld meg a data science technikai alapjait valós üzleti problémák megoldása során és lesd el a legjobb gyakorlatokat tapasztalt profiktól.
Nos, ahhoz hogy adatelemzőként illetve adatbányászként elinduljunk a data science terület irányába, talán a legjobb amit tehetünk, ha elkezdjük megtanulni a Python nyelv használatát, hiszen ez az eszköz az egyik legelterjedtebb olyan ingyenes lehetőség, amivel az adatok világában kis túlzással minden megoldható. A Python mellett szokták említeni a SAS-t és az R-t is, mint legáltalánosabb data science eszközöket, de előbbi magánszemélyeknek illetve kisebb cégeknek is gyakorlatilag elérhetetlen a brutális ára miatt, utóbbi azonban szintén egy jó választás lehet. A “Python vs. R” témakörben számtalan írás született már, melyek alapján én azt a következtetést látom, hogy pár éve még inkább az R volt a favorit az elemzői világban, mára azonban ez megfordulni látszik. Korábban a Python hiányosságai között szerepelt pl. a gyengébb grafikai megjelenítés (ábrák készítése) vagy a kisebb community, de az elmúlt 1-2 év ezeket is bőven felülírta. Előbbire példaként íme néhány Python csomag: már az alap matplotlib-bel is rengeteg féle, többszörösen összetett (osztott, több tengelyes, színezett, adatpont szinten címkézett, egymásba ágyazott stb.) ábra generálható, de 3D-s ábrák és animációk is készíthetők vele. A lehetőségeknek korlátot inkább csak a befogadói oldal szab. Ezen túl ott van pl. a seaborn, ami nagyszerű kibővített lehetőséget nyújt az extrémebb igényű adatelemzőknek is. Egyik kedvencem a tengelyekre rajzolt hisztogram, de a speciális violinplot is mennyivel többet mutat, mint egy átlag boxplot. Az sem rossz persze, hogy ezt a könyvtárat használva kb. egy kódsorral legenerálhatók bonyolultabb ábrák is, pl. egy, az adatpontokat attribútum-párok szerint megjelenítő grid, amit természetesen akár kézzel is lekódolhatunk sima matplotlib felett. Ha interaktív ábrákra van szükségünk, a bokeh és a plotly lesznek a barátaink (utóbbival pl. streaming adatok is megjeleníthetők stream-ként), de ha csak gyorsan és okosat szeretnénk az adathalmazunkról, akkor a legegyszerűbb a pandas beépített ‘plot()’ függvényét használni. Ezek a csomagok folyamatosan bővülnek, és ez csak 5 modul az adatok megjelenítésére, így nyugodtan mondhatjuk, hogy sok esetben ma már kevésbé aktuálisak az elmúlt évek Python és R összehasonlító írásai.
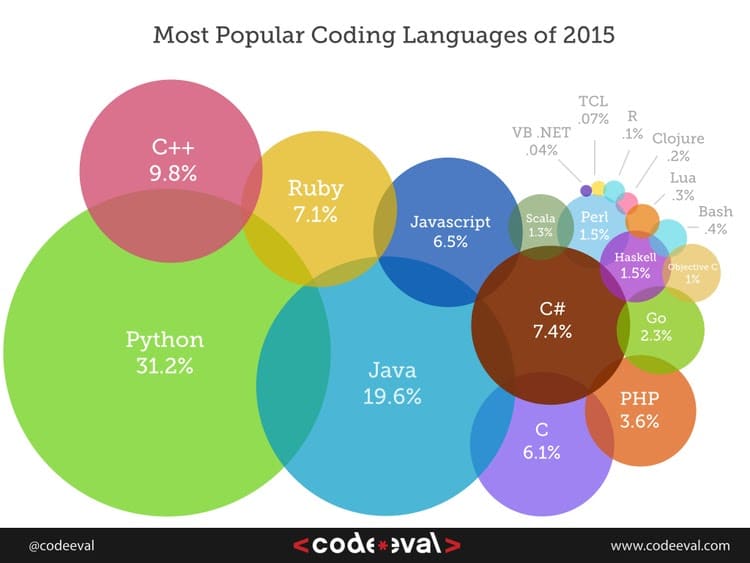
Akit esetleg bővebben érdekel a különböző adatmanipulációs eszközök és programnyelvek népszerűsége, a teljesség igénye nélkül az alábbi oldalakon sok hasznos információt talál: KDnuggets 2014 poll (lassan érkezik az idei felmérés), GitHub & Stackoverflow ranking, Most Popular Coding Languages 2015, illetve az évek óta bővülő r4stats popularity írás.
Python verziók
És akkor egy picit a Python-ról: ez a nyelv egy általános célú, magas szintű, interpreteres, in-memory szkript nyelv, és ami nagyon fontos, hogy könnyen tanulható és igen jól olvasható, ezért a kisebb programozói tudással rendelkezők is bátran belevághatnak a megismerésébe, ha pedig valakinek már régóta elege van a grafikus adatelemző szoftverek korlátaiból, akkor legfőbb ideje elkezdeni a tanulást. A fentiek többsége az R-ről kevésbé mondható el, aminek egyébiránt (“csak”) 5000 modulja van (ami szintén rengeteg!). A programozási paradigmákat illetően a Python támogatja a funkcionális, az objektumorientált, az imperatív és a procedurális metodikákat egyaránt, de mapreduce kódokat is írhatunk Python-ban.
A Python nyelvet 1989 végén kezdték el írni, ‘94-ben jelent meg az 1.0-ás verzió, 2000-ben a 2.0-ás, 2008-ban pedig a 3.0-ás. Jelenleg a 2.x és a 3.x két fő verziócsalád is aktív fejlesztés alatt áll, így ezek közül a választás amennyire triviális vagy lényegtelen, annyi “vitát” is szülhet. Pár éve még a 2-es verziók melletti igen erős érvek voltak a korábbi szkriptekkel való abszolút kompatibilitás, az összes modul elérhetősége és a tudományos világ “elkötelezettsége”, mára azonban a leggyakoribb választási tanácsként az “amelyik a célodhoz, aktuális projektedhez jobban illeszkedik” hangzik el, és több helyen is megemlítik, hogy összességében a két fő verzió közti “legnagyobb” különbség a “print” utasítás függvénnyé alakulása. Ehhez szintén viccesen csak annyit tennék hozzá, hogy a 3-as Python-ban az ‘1/3’ (1 osztva 3-mal) eredménye végre már nem ‘0’ (tiszta RapidMiner ;-). A hivatalos állásfoglalás szerint a “Python 2.x is legacy, Python 3.x is the present and future of the language”. A különbségekről egy részletesebb lista itt található. Saját részről mivel az egyik legjobb Python-os adatbányászati csomag, az sklearn is csak a 2.6-os illetve 3.3-as verzióktól támogatott, és előbbi már 2008-tól elérhető, míg utóbbi csak 2012-től (igaz, maga az sklearn is csak 2010-től), így én is a 2.x-es verziót kezdtem el használni. A két verzió szerencsére tökéletesen megfér egymás mellett (lásd lentebb), és mindkettő elérhető nagyjából az összes platformra.
Python telepítése
Ennyi bevezető legyen is elég, ideje telepíteni a gépünkre a Python-t. Választhatjuk a standard Python telepítőt, amivel kapunk egy parancssori értelmezőt, ami alatt egy Python shell fut. A standard könyvtár igen kiterjedt, számos beépített objektumot, függvényt, konstanst, kivételt, metódust (pl. sztring műveletekre), adattípust, matematikai modult, operációs rendszer szintű és multimédia szolgáltatást valamint webes eszközöket tartalmaz, így már önmagában ezzel is egész komoly feladatok oldhatók meg. Azonban adatelemzőként (és egyébként is) biztosan többre lesz szükségünk, így külső modulokat kell majd telepíteni. Vannak akik szeretik precízen tudni, hogy pontosan mi és hol van a számítógépükön, így ők biztosan külön, egyesével telepítik a számukra aktuálisan szükséges csomagokat. Szerintem viszont (általános célra) sokkal egyszerűbb valamely elterjedt Python disztribúciót használni, mint amilyen például az Anaconda. Projektekhez nyilván speciális, testre szabott Python környezeteket használunk. A magam részéről az Anacondával tökéletesen meg vagyok elégedve, így nem tudom más eszközökkel összehasonlítani (mert nem próbáltam mást). Ingyenes, a legtöbb data science Python modult tartalmazza (több, mint 270 csomagot foglal magába), illetve akadémiai licenccel elérhető hozzá néhány extra (GPU, memória és CPU boost) kiegészítés is. Célszerű (a telepítéskor) ezt a Python-t beállítani alapértelmezettként, így újabb modulok a szokásos módon is telepíthetők (Windows alatt pl. python setup.py install). Parancssorban a conda list utasítás kiadásával kilistázhatók a feltelepített csomagok. Windows-ra a ‘.whl’ (wheel – speciális ZIP formátum Python csomagok telepítésére) kiterjesztésű állományok az alábbi paranccsal tehetők fel: <Anaconda home>\Scripts\pip.exe install <abc>.whl. Ezen az oldalon számos olyan Python modul érhető el Windows-ra, amit hivatalosan csak Linux-ra publikáltak. Ilyen pl. a magyar fejlesztésű igraph, ami a legtöbb esetben egy-két nagyságrenddel hatékonyabb, mint a szintén gráfanalitikai networkx modul. De ha komolyabban akarunk foglalkozni hálózatelemzéssel, akkor a graph-tool csomagot célszerű használnunk (a nagyobb performancia, akárcsak az igraph esetén, a C-ben ill. C++-ban (nem pedig Python-ban) írt algoritmusoknak köszönhető). A fenti csomagok tehát nem részei az Anaconda repository-nak. Ha az alapértelmezett repository csatornákhoz újabbakat szeretnénk felvenni, akkor a felhasználó home könyvtárában létre kell hozni egy .condarc nevű fájlt, amibe be kell másolni az összes, régi és új csatorna URL-t. A conda install <csomag neve> paranccsal telepíthetők a repository-kból elérhető modulok. Egy (repository-ból) telepített csomag frissítése a conda update <csomag neve> paranccsal történik. Erre néha szükség lehet, mert a teljes Anaconda összeállításba (telepítőbe) nem kerülnek be azonnal az egyes Python csomagok legújabb verziói (pl. aktuálisan a pár hete megjelent pandas 0.16.0), de a repository-ba igen. Vagyis csupán az Anaconda frissítésével, azaz a conda update conda illetve conda update anaconda utasításokkal nem feltétlenül kerülnek fel a gépünkre a legújabb Python csomagok. A fenti utasítások mindegyike nyugodtan kiadható teszt jelleggel is, mert mindig van egy megerősítő kérdés a telepítéshez illetve frissítéshez, ahol kilistázásra kerülnek az aktuális (lecserélendő) és új verziójú csomagok (a megadott Python modul és automatikusan a függőségei is).
Python használata
Ha egy projekt erejéig, vagy csak teszt jelleggel más Python környezetre van szükségünk, pl. 2.7.x helyett 3.4.x verziójú Python-ra, vagy csak egy új vagy speciális Python csomagot szeretnénk kipróbálni, esetleg különböző Python csomagok egymásra hatását vizsgáljuk, akkor létrehozhatunk az Anacondán belül Python környezeteket, amik az <Anaconda home>\envs\ könyvtárba kerülnek. Például egy teljes Anaconda Python 3.4-es környezet a conda create -n <Python környezet neve> python=3.4 anaconda paranccsal hozható létre, de ha lehagyjuk a végéről az “anaconda” paramétert, akkor csak a megadott (verziójú) modul illetve automatikusan annak függőségei kerülnek feltelepítésre az adott nevű környezetbe. Parancssorban Python környezetet az activate <Python környezet neve> utasítással aktiválhatunk, a deactivate utasítással pedig visszatérhetünk az alapértelmezetten telepített Anaconda Python környezetbe (a python -V utasítással ellenőrizhetjük az aktív Python interpreter verzióját). Ezek az utasítások (batch fájlok) az Anaconda telepítésekor automatikusan hozzáadódnak a PATH-hoz, de egyébként az <Anaconda home>\Scripts\ mappa alatt fizikailag is megtalálhatók.
Szkripteket Spyder-ben érdemes írni (az Anaconda automatikusan feltelepíti), ahol a bal oldali szerkesztőfelületen készíthető el egy-egy program, a jobb alsó IPython (Interaktív Python) konzolban pedig futtatható a kód. Célszerű lehet a létrehozott Python szkripteket egy online könyvtár alá gyűjteni (pl. Google Drive vagy Dropbox), így bármikor bárhonnan elérhetők lesznek, ahol van net. A futtatáshoz természetesen használhatjuk a normál Python konzolt is az IPython konzol helyett, de az utóbbi ajánlott a számos előnye és kényelmi funkciója miatt. Egyszerre több konzolt is megnyithatunk, amikor is mindegyikhez külön Python kernel rendelődik, azonban mindegyik ugyanazon Python környezethez tartozik. Windows alatt a Spyder-rel egy ‘pythonw.exe’ és ez alól annyi ‘python.exe’ alkalmazás indul el, ahány (Python és IPython) konzolt, vagyis kernelt futtatunk (tehát nem az ‘ipython.exe’ fut, annak ellenére, hogy IPython konzolt is használunk). Ha több Python környezetünk van, célszerű mindegyikhez másolni egy Spyder parancsikont (a Start Menüből) az eredetihez hasonlóan, ügyelve az elérési utak megfelelő aktualizálására (\envs\<Python környezet neve> hozzáadása). 2.x-es és 3.x-es Python kernelt használó Spyder-ből csak egy-egy futtatható egyszerre (egymás mellett), tehát pl. két eltérő 2.7.x-es Python környezethez tartozó kernel nem.
Célszerű lehet a Spyder template-et saját ízlésünk szerint kiegészíteni, így egy új szkript írásának kezdetén (Ctr+N) már nem kell minden alkalommal begépelnünk pl. a szokásos import numpy as np, import pandas as pd stb. sorokat. Minden újonnan megnyitott konzolban egyszer (elsőként) érdemes lefuttatni néhány pandas-os beállítást, melyekkel a dataframe-k (pandas “táblázatok”) megjelenítési paraméterei állíthatók be tetszés szerinti értékekre. A pandas (panel datas) Python-ban az adatelemzés alapmodulja, ahol az adattáblákat dataframe-ekben (kétdimenziós adat panelekben) tároljuk, amiken mindenféle adatmanipuláció, elemzés, modellezés stb. könnyen, gyorsan és nagyon hatékonyan elvégezhető. Az egydimenziós “dataframe” a Series objektum (egy adatsor), a kétdimenziós a DataFrame objektum (táblázat), a három dimenziós pedig a Panel (3D mátrix), de léteznek Panel4D és PanelND objektumok is. A pandas mélységeiről talán majd később, illetve addig is mindenki használja a netet.
A Spyder-ben a pd.set_option(‘display.width’,1000) és pd.set_option( ‘max_colwidth’,70) parancsokkal adható meg a dataframe illetve az oszlopok nagyobb szélessége, alapértelmezetten ugyanis a pandas 80 karakterenként tördeli a sorokat, ami eléggé olvashatatlanná tudja tenni a nagyobb adattáblákat (az alapértelmezett oszlopszélesség pedig 50 karakter). Ha a szkriptünket bemeneti argumentumokkal szeretnénk futtatni Spyder-ből, akkor az F5 billentyű (= aktuális szkript futtatása) előtt nyomjuk meg az F6 billentyűt (= futtatás beállításai), és adjuk meg a kívánt parancssori argumentumokat. Ha a programunknak csak a szerkesztőben kijelölt egy részletét szeretnénk futtatni, akkor az F9-et nyomjuk meg a megfelelő kijelölés után. Ha futtattunk egy szkriptet (és még nem zártuk be a kernelt), akkor a futás utolsó pillanatában meglévő minden adat továbbra is elérhető a memóriából, vagyis a konzolban nyugodtan beírhatjuk pl. hogy print my_var, és ha volt ilyen nevű változónk (és a kódban nem töröltük azt), akkor megjelenik az értéke. Tehát nem szükséges a kódba utólag beírni ezt az utasítást és újrafuttatni a teljes szkriptet csak azért, mert futás közben elfelejtettük kiprintelni valamely változó végső értékét.
IPython Notebook
A fentebb említett IPython konzolnak illetve kernelnek az interaktivitása, “varázslata“, rugalmassága, “klaszterezhetősége“, beágyazhatósága stb. mellett a legnagyobb gyakorlati haszna, hogy általa futtathatók IPython Notebook szerverek (az Anacondának köszönhetően mindezt egy kattintással és természetesen a saját desktop gépünkön). Az IPython nem összetévesztendő a Python-nal: előbbi csupán a Python környezet egy modulja. Egy IPython Notebook szerver egy interaktív webes Python fejlesztőeszközt nyújt, ahol egy-egy cellába egy összetartozó kódblokk írható, majd a létrehozott teljes Notebook szkript cellánként futtatható. Kiválóan alkalmas tanulásra, oktatásra (rengeteg tutorial ebben készült) illetve prezentációra is. Indításakor Windows-on az ‘ipython.exe’ alkalmazás indul el, ami futtat egy “központi vezérlő” Python kernelt (‘python.exe’ állományt) illetve ez alól további annyi kernelt (szintén ‘python.exe’ fájlt), ahány Notebook szkriptet megnyitottunk a kedvenc böngészőnkben. IPython Notebook futtatókörnyezetből már annyit megnyithatunk egymás mellett, ahány Python környezetünk van, függetlenül azok fő- vagy alverzióitól. Pár napja jelent meg az IPython 3.1 verzió, ami a februári kiadású 3.0 verzióval egyetemben jó pár alapvető dologban eltér a korábbi IPython 2.x verzióktól, így adott esetben szükségünk lehet olyan Python környezetre, ami például Python 2.7.x alapon nyújt IPython 2.x felületet, illetve egy másik szintén Python 2.7.x környezetre, de már IPython 3.x csomaggal. Ugyanez igaz lehet a Python 3.x-re is. IPython 3.x alatt (egy fél-automatikus konverziót követően) futtathatók ugyan a korábbi IPython 2.x Notebook fájlok, de fordítva sajnos ez nem igaz. Az egyes IPython Notebook környezeteknek is célszerű lehet külön-külön, egyértelmű elnevezéssel (Python ill. IPython verziókkal) ellátott parancsikonokat létrehozni. Ha esetleg az újabb verziójú Anaconda telepítésével nem kerülne be egy alap IPython Notebook parancsikon a Start Menübe, akkor az általunk kreáltnak az alábbi ‘Cél’-t kell tartalmaznia: <Anaconda home>\Scripts\ipython.exe “<Anaconda home>\Scripts\ipython-script.py” notebook. Fontos, hogy az ‘Indítás helyé”-nek olyan (szintén online) mappát adjunk meg, ahol tárolni szeretnénk a Notebook szkriptjeinket, így a szerver indítását követően automatikusan megnyíló kezdőoldal azonnal kilistázza azokat. A kernelekre picit még visszatérve: ki nem találnánk, így leírom, hogy önmagában egy darab IPython Notebook szerveren különböző Python kernelek (környezetek) felett is futtathatók a szkriptjeink, egy kattintással. Ha ez nem volna elég, durvulhatunk is 🙂
Ja igen, akit zavar az IPython Notebook weblap kinézete, használhat teljesen egyedi CSS-t a megjelenítéshez. Én azt szoktam beállítani, hogy a cellák balra igazítva jelenjenek meg, ne pedig középen, illetve hogy a szélességük jó nagy legyen, hogy “elférjenek benne” az adattáblák. Ehhez az alábbi tartalmú CSS fájlra lesz szükségünk (a lenti my_style.css fájlt tegyük pl. a fenti “Indítás helye” mappába):
Ezt az alábbi kóddal tölthetjük be az aktuális IPython Notebook szkriptünkbe:
<style>
.container {
width:100% !important;
}
div.cell {
width:1700px;
margin-left:1px;
margin-right:1px;
}
</style>
Ezt az alábbi kóddal tölthetjük be az aktuális IPython Notebook szkriptünkbe:
from IPython.core.display import HTML
def css_styling():
styles=open(“./my_style.css”,”r”).read()
return HTML(styles) css_styling()
css_styling()
A fenti cellát futtatni a Ctr+Enter billentyűk lenyomásával a legegyszerűbb. A széles dataframe-ekhez természetesen a fentebb írt pandas-os beállításokat is le kell futtatni egyszer kernelenként (megnyitott Notebook szkriptenként).
Nos, a poszt végére, ha a cikk közbeni linkek nem lettek volna elegendők, már csak néhány IPython Notebook illetve Pandas tutorialt tennék be, szintén a teljesség igénye nélkül:
- Python alapok IPython Notebook-ban
- Pandas tutorialok
- A Short Intro to Pandas IPython Notebook-ban
- IPython Notebook + Bokeh
- IPython Notebook + Plotly
Jó szórakozást!
A kép forrása.
 Vissza a blogbejegyzésekhez
Vissza a blogbejegyzésekhez