Machine Learning összefoglaló 2020

2020.12.17. • olvasási idő:
A 2020-as évben a gépi tanulás különböző területein számos előrelépések történtek. Egyre közelebb kerülünk ahhoz, hogy az AI alapú megoldások elterjedjenek és egyre szélesebb körben kezdjék el azokat használni is. Ebben a blogpostban a 2020-as év Machine Learning trendjeit vesszük górcső alá, és nézzük meg őket kicsit részletesebben.

A cikk eredetileg a Medium blogon jelent meg angolul, készítettünk hozzá azonban egy magyar öszzefoglalót, a teljes cikk alább megtalálható eredeti nyelven.
A magyarázható mesterséges intelligencia (Explainable AI) iránti igény egyre sürgetőbb lesz, ez az amely valójában fel tudja gyorsítani a gépi tanuló modellek elterjedését sok szegmensben. A Full Stack Data Scientist pozíció is elkezdett kialakulni, melynek az oka, hogy minden eddiginél nagyobb figyelmet kap az MLOps mivel a mostani AutoML-es és egyéb state-of-the-art megoldásoknak hála jelenleg nem ez a legnehezebb feladat egy data science projektben. Az év elején megjelent, az OpenAI által fejlesztett GPT-3-as modell eggyel magasabb szintre emelte a nyelvi modelleket, és már az ember alkotta szöveghez szinte teljesen hasonlókat tudunk a segítségével készíteni. Az év vége felé pedig a DeepMindosok hatalmas áttörést értek el az AlphaFold eszközükkel, amellyel minden eddiginél pontosabban megtudják alkotni egy fehérje 3D-s struktúráját.
Review of Machine Learning 2020
We made a lot of progress this year in the field of Machine Learning. The proliferation of AI-based solutions among non-tech companies is getting closer and closer. To be honest, I think we’ve accomplished a lot, but we still have a long way to go. We have to regulate this field and can’t let it loose because it would lead to a more diverged and unequal world rather than a better one. Let’s recap what was 2020 all about in the field of Machine Learning and Data Science.
Interpretable Machine Learning / Explainable AI
From development aspects, we used to call the machine learning models black-box and even didn’t wanted to try to explain its working mechanism. We just laid back and waited that the business will just simply trust in us and accept these black-box models. This is simply not what the business wants. This is not enough for the people who will use these solutions and have to deal with the mistakes which they made. Tho models never have to deal with the real-life consequences of their decisions, people have.
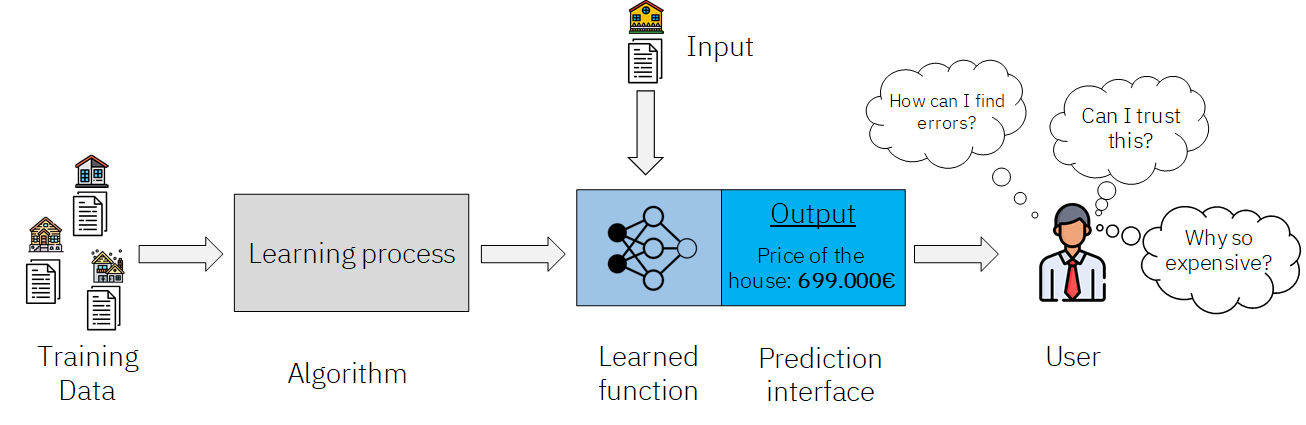
Machine Learning workflow (Source:Jamine Zorzona)
If the predictions come without any justification the users have to blindly trust in the model. Although if people understand why the model is saying what it is saying that could boost the trust in it. This field got a lot of attention this year, and this will hopefully continue in 2021. The reasons why this field becomes one of the most important is that :
- The digital transformation is still in progress at most of the big companies. They are just exploring the newest tech solutions, to adopt a system which they did not understand and rely on that that is something which not gonna work. Understanding what happens when a ML model makes its prediction will definitely speed up the widespread of these systems.
- Not just because of the “right to explanation” article by the EU which is tend to regulate the automated decision-making process but buy now there are some sectors such as banking and insurance where is a must that the models which they use have to be explainable.
- The trust in the models is more important in the field of medicine and healthcare where these systems can make a real impact on humankind. Providing more information not just the result to the people can increase their trust in the prediction.
This list could contain many more examples, but I guess you got the point that this field is extremely important and we just can’t ignore it anymore if we want to make progress and spread the so-called “AI-driven solutions” in the business.
Automated Machine Learning
AutoML is getting so much attention this year, several companies are working on their own solutions. I personally have some concerns about it, and that’s not because of the fear that ohh wow automated machine learning will take my job. Simply because of that, the users of the AutoML systems are not the ones who should be.
AutoML is a great field to automate the modeling process and generate new features for us, do the data preprocessing phase, select the model, and tune its hyperparameters.
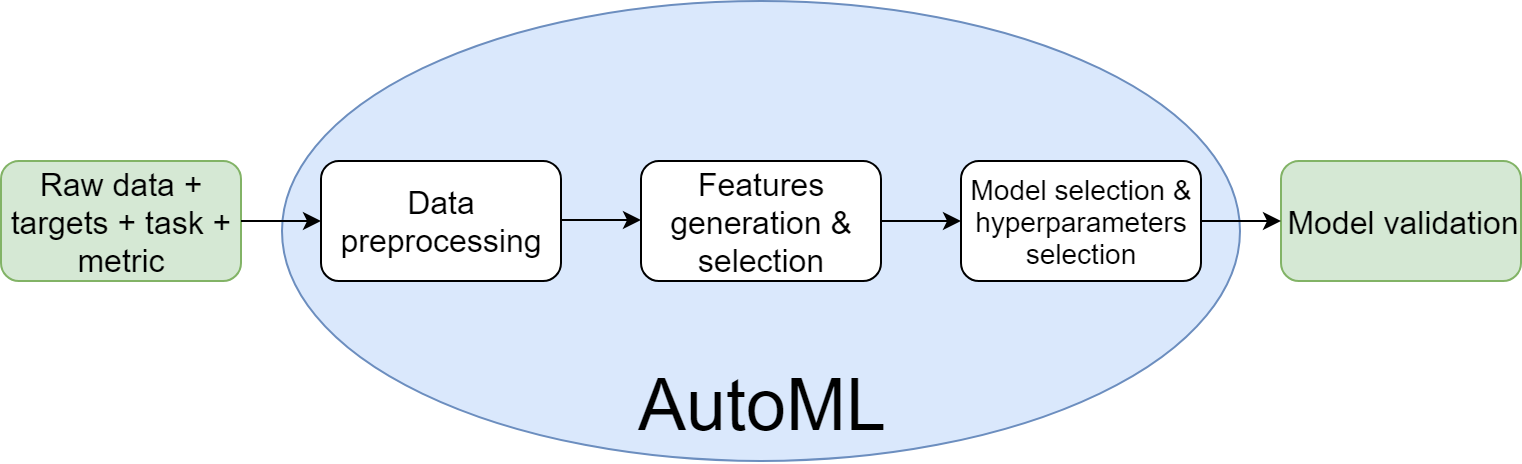
Automated machine learning (Source:Deni Vorotyntsev)
That’s nice and good so far, but Auto ML is or should be a tool not a replacement of a Data Science team. With AutoML tools, you can save time and automate the modeling process as a data scientist and relatively fast receive results that can be presented. But it definitely doesn’t manage to do the whole CRISP-DM process just one step from it. That step is, by the way, one of the most important but without context, we will receive just a model not a solution for a problem.
After the hating part, we should acknowledge that both 3 big cloud providers( AWS, GCP, and Azure) making decent progress with their AutoML solution. The leader of this competition is currently H2O AutoML which not only provides the best accuracy but became so popular among the AutoML users due to its easy to use feature. We should also mention AutoKeras which first official release was early this year. It relies on the popular deep learning libraries, Keras and Tensorflow. Accuracy is not the only key metric which we should track, scalability, flexibility, and transparency are almost as important as the first one.
Full Stack Data Scientists
Full stack developers are all around us for several years in the world of web development. It was just a matter of time when these special species will evolve for the data field.
By now data scientists already know what to use and how to use, like CNN models for computer vision, tree based methods for tabular data, and which transformers are suggested for NLP problems. So many state-of-the-art models are out now we just have to know how to use them. This means for data science projects the data preprocessing and modeling are not the hardest part anymore.
The main challenges for the data science teams are deploying and maintaining the models in production. Therefore MLOps becomes more and more important and software engineering and DevOps skills are highly appreciated for a data scientist. Creating a good model that runs only locally is not enough anymore building an end-to-end system that includes dockerizing the solution and operating it on-premise or in the cloud is a more reasonable expectation from a data scientist.
AI pioneers
To be honest, this paragraph would be totally different if I wrote it in November, probably I would mention DeepMind in one sentence just to establish the praise of OpenAI which created the GPT-3 model, a mindblowing language model with a lot of capabilities. But since then it turned out that the newest AI tool from DeepMind the AlphaFold is making a scientific breakthrough.
AlphaFold
AlphaFold can accurately predict 3D models of protein structures and has the potential to accelerate research in every field of biology. Firstly I thought hmm that’s not bad but nothing special at all. When I dig into this topic I just realized how big it actually is. AlphaFold can accurately predict the protein’s shape from its sequence of amino acids. There are more than 200 million proteins that build up from the combination of 20 different types of amino acids. Until now the scientist revealed just the fragment of the 3D protein models. AlphaFold performs over 90% match in the global distance test at protein folding, which means they solved the problem of protein folding. This huge achievement doesn’t make such a great impact directly onto our life but it can accelerate the research progress in so many areas
GPT-3
The newest generation of OpenAI’s language prediction models. The previous one the GPT-2 was fully released just 6 months after its original release due to concerns about it. It is so powerful that it could easily write fake news, fill emails, and so on. This model contains 1,5 billion parameters which is just a tiny amount compared to the newest generation GPT-3 which contains 175 billion parameters. The quality of the texts generated by GPT-3 is so perfect that distinguish them from the human-written text is nearly impossible. GPT-3 can create anything that has a language structure which means it can answer questions, write essays, summarize long texts, translate languages, take memos, and even create computer code. GPT-3 as well as their ancestors is a pre-trained model so the user can feed the text as an input to the model which generates the output for it. To be able to perform at such a high-level OpenAI has to spend about 4.6 million dollars to train the model. The result is fascinating but also so powerful that it’s not open yet for the average person so to get access to it you should request it from OpenAI and join to its waiting list. Once it will be released Microsoft will operate it on Azure.

Summary
2020 was an interesting year from so many aspects I think 2021 will bring several new and exciting topics to us. The need for explainable AI will be more urgent, and the rise of the full stack data scientist will become and there will be more attention on MLOps than ever. I am pretty curious about the GPT-3 API and can’t wait to use it. I also think that to feel the actual result of the huge achievement by AlphaFold is a couple of years far from us. So this was my yearly recap about the most interesting topics from the field of Machine Learning and data science
 Vissza a blogbejegyzésekhez
Vissza a blogbejegyzésekhez