A reinforcement learning alapjai

2020.06.11. • olvasási idő:
A reinforcement learning a gépi tanulás világának egy kevésbé ismert, azonban nagy lehetőségeket tartogató területe, ezt mutatjuk be ebben a posztunkban.

A médiában időről időre felbukkannak olyan hírek, minthogy az AI képes megverni a sakk, a go, és a skógi játékok regnáló bajnokait, valamint hogy a legjobb Dota játékosokat is képes legyőzni. Mindezek mögött valójában a gépi tanulás egy kevésbé ismert ágazata, a reinforcement learning, azaz a megerősítéses tanulás rejlik. Ennél a módszernél a gépi tanuló algoritmus kezdetben zéró tudással rendelkezik; csak úgy, mint egy élőlény, a környezetének hatásaira reagálva dönti el, hogy a cselekvés, amelyet végrehajt helyes-e vagy sem.
A robotikában mára már fizikailag szinte tökéletes hardvereket tudunk építeni. A probléma csupán az, hogy ezeket nem tudjuk felruházni a szükséges intelligenciával, hogy azokból általános feladatokat ellátó robotokat tudjunk készíteni. Így a robotok készítése mára már inkább szoftveres kihívás, mintsem hardveres. Olyan feladatok megtanulása, mint hogy egy étteremben egy robot szolgáljon fel ételeket rendkívül komplex és kihívásokkal teli terület, amint azt áthelyezzük az étteremlánc egy másik egységébe. Ilyen és ehhez hasonló feladatokat tudunk megoldani a megerősítéses tanulás segítségével, habár a gépi tanulás más típusait az iparban már jó ideje sikeresen használjuk a megerősítéses tanulás széleskörű elterjedése és éles rendszerekben való alkalmazása még várat magára.

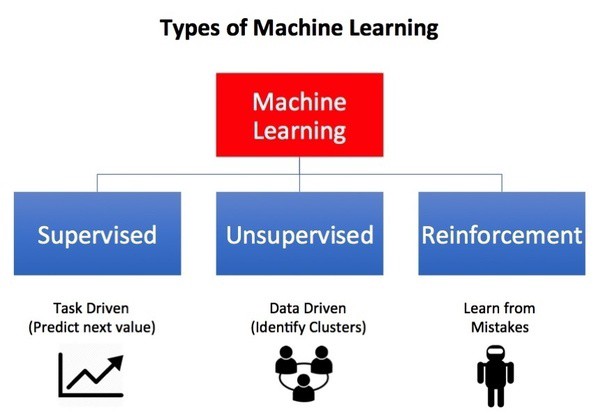
Mi is pontosan a megerősítéses tanulás és miben különbözik a többi gépi tanulástól?
Forrás: www.towardsdatascience.com
Reinforcement learning vs supervised learning
A felügyelt tanulás során a modellünk „tudja”, hogy milyen feladatot kell végrehajtania, és melyik művelet helyes. Mi, data scientistek a modelleket címkézett historikus adatokkal tanítjuk, hogy predikciókat tudjunk tenni velük a célváltozóra vonatkozóan. A felügyelt tanulást osztályozási és regressziós feladatok megoldásához szoktuk használni.
Ezzel szemben a megerősítéses tanulás (reinforcement learning) nem támaszkodik a címkézett adatkészletekre, itt a modellnek nem mondjuk meg, hogy mely műveleteket kell végrehajtania, vagy épp a feladat optimális végrehajtásának módját. A megerősítéses tanulásnál jutalmakat és büntetéseket használunk az egyes döntésekhez kapcsolódó címkék helyett annak jelzésére, hogy a megtett művelet jó vagy rossz. Tehát a modellünk csak akkor kap visszajelzést, amikor elvégzi a teljes feladatot. Az időben késleltetett visszacsatolással és a trial and error elv alapú működéssel lehet megkülönböztetni a megerősítéses tanulást a felügyelt tanulástól. Továbbá a megerősítéses tanulás egyik célja, hogy helyes egymást követő tevékenységeket találjon, amelyek maximalizálják a jutalmat. Ez a szekvenciális döntéshozatal a másik jelentős különbség az algoritmusok stílusai között.
Reinforcement learning vs unsupervised learning
Felügyelet nélküli tanulás során az algoritmus elemzi az adatokat (címkézetlen adatok), hogy rejtett összefüggéseket keressen az adatpontok között, és hasonlóságok vagy különbségek alapján strukturálja azokat. A megerősítéses tanulás célja a legjobb cselekvési modell meghatározása a legnagyobb hosszú távú haszon megszerzése érdekében, megkülönböztetve azt a fő céljától a felügyelet nélküli tanulással szemben.
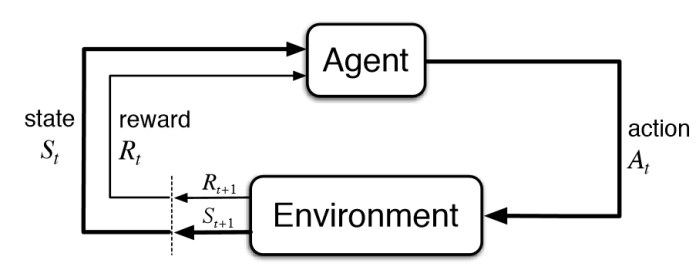
Mi a reinforcement learning pontosan?
Forrás: www.kdnuggets.com
Maga a megerősítéses tanulás egy természetes mintán alapul: a környezettel való interakción keresztül megtanuljuk, hogyan kell viselkedni különböző helyzetekben. A világot a saját tapasztalataink alapján kell felfedeznünk, nincs olyan példa, ahonnan mindent lemásolhatnánk. A megerősítéses tanulás vizsgálata sokféle aspektusból történhet, legyen szó akár pedagógiai, pszichológiai vagy matematikai nézőpontról.
A megerősítéses tanulás során a tanuló ágensünk műveleteket hajt végre egy adott környezetben. A gépi tanulás világában ágens lehet bármi, amely döntéseket hoz; egy személy, egy gép vagy akár egy szoftver. Az ágens olyan döntést hoz, amit a múltbéli tapasztalatai alapján, illetve jelen helyzetét megvizsgálva a legmegfelelőbbnek ítél meg. Így tehát az ágens figyelemmel kíséri a környezet jelenlegi állapotát, kiválasztja a végrehajtható műveletek egyikét és teljesíti azt. Az ágens minden művelet után egy másik állapotba kerül, ahol először megfigyel, majd ismét kiválasztja és végrehajtja a szerinte legjobb műveletet. Egyes állapotokhoz jutalmat rendelhetünk, amelyet az ágensünk akkor kap meg, amikor eléri azokat. Az ágensünk célja a megerősítéses tanulás során a megszerzett jutalom maximalizálása.
A megerősítéses tanulás lényegét legjobban a felügyelt tanulástól való eltérése szemlélteti. A megerősítéses tanulás jellemzője, hogy a jutalom általában időben késve jelentkezik. Ez azt jelenti, hogy a visszacsatolást, amely arról szól, hogy az ágensünk sikeres volt-e, vagy sem, csak bizonyos számú művelet elvégzése után kapjuk meg. Ezzel szemben a felügyelt tanulásban a modell azonnal tudja, hogy a művelet sikeres volt-e vagy sem, mivel a visszajelzés azonnali. Felügyelt tanulási esetekben van egy “tanár”, aki elmondja, hogy mi az optimális cselekedet az egyes helyzetekben. Ugyanakkor a megerősítéses tanulásban a tanuló ágens saját maga fedezi fel mindazt, hogy az adott környezetben mely tevékenységek, műveletek bizonyulnak helyesnek azáltal, hogy kipróbálja őket. A legtöbb esetben az ágens által választott tevékenységek nemcsak az azonnali jutalmat befolyásolják, hanem azt az állapotot is, amelybe a tanuló ágens ezt követően belép, és így közvetetten az összes további jutalmat is. Ez a két tulajdonság – a cselekvés végrehajtása try and error jelleggel, valamint az azonnali és hosszú távú jutalom maximalizálása – a megerősítéses tanulás két legfontosabb jellemzője.
A megerősítéses tanulási probléma megoldásához a tanuló ágensnek bizonyos mértékig tisztában kell lennie környezetének állapotával, és képesnek kell lennie arra, hogy befolyásolja azt. Az ágens célja alapvetően a megszerezhető jutalom maximalizálása, mely jutalom származhat például egy kívánt célállapot eléréséből. A megerősítéses tanulásnál teljesen más kihívással nézünk szembe, mint a többi típusú tanulásnál; ebben az esetben a célunk az, hogy az ágens megtalálja az egyensúlyt a felfedezés és a jutalom elérése között. Annak érdekében, hogy sok jutalmat halmozhasson fel, az ágensnek ki kell választania azokat a cselekedeteket, amelyeket már megpróbált a múltban, és magas jutalommal kecsegtettek. Ahhoz, hogy felfedezze az ilyen kiemelten kifizetődő tevékenységeket, ki kell próbálnia azokat, amelyekkel korábban még nem kísérletezett. Tehát az ágensnek a saját tudását kell használnia, hogy jutalomhoz jusson, miközben feltárja környezetét és cselekedeteit, hogy a jövőben a lehető legjobb döntéseket tudja meghozni. Azonban fontos, hogy nem lehet csupán a maximális jutalomra koncentrálni, hiszen mindenféleképpen el kell végeznie a számára kitűzött feladatot. Az ágensnek különféle tevékenységeket kell kipróbálnia, és azokat kell előnyben részesítenie, amelyek a legnagyobb haszonnal járnak.
A megerősítéses tanulás során élhetünk azzal a feltételezéssel, miszerint a környezet, amelyben a tanuló ágens szerepel bizonytalan, azaz nem teljes egészében ismert vagy nem teljesen megfigyelhető. Mindezek alapján a megerősítéses tanulásnál nem elég a tanuló ágensünket fejleszteni, hanem időt és erőforrást kell szánni a megfelelő környezeti modell előállítására és annak folyamatos fejlesztésére.
Milyen alkalmazásai vannak manapság, hol és mire használják a megerősítéses tanulást?
Mára már számos területen elterjedt a reinforcement learning-en alapuló alkalmazások használata, mint például:
Robotika – Robot mozgás

Ipari automatizáció – Önvezető autók

Repülőgép kontroll, szabályozás – Quadrotor

Kik fejlesztik most, mi mire tudjuk használni és hogyan készíthetünk ilyen megoldást?
A reinforcement learning világában a Python programnyelv dominál; ebben született a legtöbb implementáció, valamint a legnépszerűbb reinforcement learning keretrendszerek is Python nyelven íródtak, ennek legfőbb oka, hogy a gépi tanulás világának a Python a fő nyelve. A megerősítéses tanuláshoz elérhető package-ket általában valamely nagy kutatócsoport készíti el, mint például az Elon Musk által alapított OpenAI vagy a Google AI kutató csoportja, a DeepMind. Ezek tartalmazzák a legfrissebb kutatási eredményeken alapuló algoritmusokat, azonban fontos megjegyezni, hogy ez a terület rendkívül fiatalnak tekinthető, így számos megoldás és csomag nem eléggé stabil. A jövő azonban mindenképp bíztató ezzel a területtel kapcsolatban; a következő nagy lépések a mesterséges intelligencia területén vélhetően itt fognak végbemenni.
 Vissza a blogbejegyzésekhez
Vissza a blogbejegyzésekhez